
Related Video
In this four-part article, we will develop a basic implementation of the original Logo programming language in JavaScript by creating a Lexer and a Parser. To render the graphics, we will parse the Logo statements and compile an HTML output file that consists of an SVG element.
Before proceeding, let's take a moment to look at some Logo programming code.
Listing 1
FORWARD 100
RIGHT 90
FORWARD 100
RIGHT 90
FORWARD 100
RIGHT 90
FORWARD 100
The code in Listing 1 above shows a complete set of statements required to produce a square shape. The command FORWARD 100 and RIGHT 90 can be thought of as function names that accept a single argument. Logo's syntax allows for more complex statements such as loops. The code above can be rewritten to use the REPEAT statement as shown below.
Listing 2
REPEAT 4 [
FORWARD 100
RIGHT 90
]
Repeat statements can also be nested. The code below shows how to produce a square using nested loops.
Listing 3
REPEAT 2 [
REPEAT 2 [
FORWARD 100
RIGHT 90
]
]
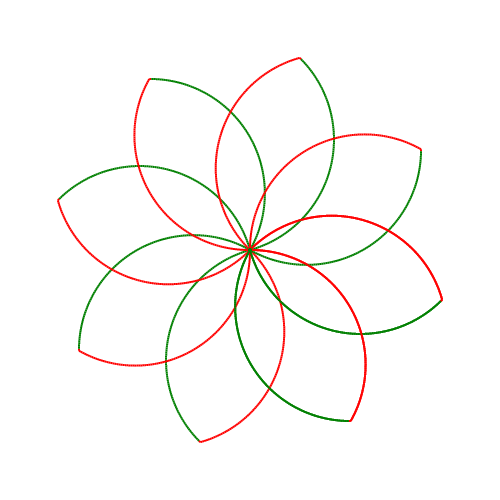
The use of loops allows a Logo developer to create complex shapes and patterns without having to write a lot of code. Take a look at the code sample below and the image it produces.
Listing 4
REPEAT 10 [
RIGHT 45
REPEAT 120 [
FORWARD 2
RIGHT 1
PENCOLOR RED
]
RIGHT 60
REPEAT 120 [
FORWARD 2
RIGHT 1
PENCOLOR GREEN
]
RIGHT 60
]
Lexer
The first task in developing the Logo language is to read a given source code and break it down into small units. These units are typically called a lexeme or more commonly a token. In computer science, a lexer is used to perform lexical analysis on a sequence of characters and symbols and give meaning to each lexeme when a match occurs. Let's take a look at an example for a better understanding. Consider the following statement below.
Listing 5
print 5 + ( 2 * x )
In order to process this statement, a lexer will need to break it down into tokens. The simplest way to tokenize this statement is to split it on white space characters which will produce the following array of tokens.
Listing 6
array[
print,
5,
+,
(,
2,
*,
x,
)
]
This approach will only work if words and symbols are separated by a space character in the source input. Consider the following two expressions. Both are valid but only the first expression can be tokenized using the space character.
Listing 7
//Characters separated by a space character
5 + 5
// No space character
5+5
We can solve this problem by splitting on more than one character using regular expressions. If you have used regular expressions before, you will know that the special pipe | character is used to denote an OR operation. Since we need to split on one or more characters, we can use the | character to construct a regular expression. Let's take a look at a JavaScript function that can take an input source and tokenize it using a regular expression pattern.
Listing 8
let str = "print 5 + ( 2 * x )";
function tokenize(str){
let regex = new RegExp(/( |\+|-|\*|\/|\(|\))/);
return str.split(regex);
}
let tokens = tokenize(str);
console.log(tokens);
The tokenize() function splits an input string using multiple characters space, +, -, *, /, (, ). You may have noticed that the pattern also includes backslashes \. This is because some characters such as the + and * have a special meaning in regular expressions and as a result, we need to escape these characters using a backslash.
We now have a collection of tokens that we can parse using a parser. However, a lexer not only tokenizes a string but also gives meaning to each token that describes the token type. For example we can say that the token 1 is of type INT and * is of type OPERATOR. Additionally most lexers will also include a line number, which is helpful when generating syntax error messages.
While we can use regular expressions to capture named groups that we can use for the token type, I personally find this approach complicated and hard to maintain and so we will rewrite the tokenize() function and remove the regular expression. Instead, we will use a loop to read one character at a time. This process can be broken down into the following steps.
Let's take a look at the updated tokenize() function.
Listing 9
function tokenize(str){
// Split the string on new lines.
let lines = str.split("\n");
let strToken = '';
let tokens = [];
let symbols = {
' ' : 'T_SPACE',
'+' : 'T_PLUS',
'-' : 'T_MINUS',
'*' : 'T_MULTIPLY',
'/' : 'T_DIVIDE',
'(' : 'T_LEFT_PAREN',
')' : 'T_RIGHT_PAREN',
'[' : 'T_LEFT_BRACKET',
']' : 'T_RIGHT_BRACKET'
};
// Iterate over each line
for(let i=0; i < lines.length; i++){
let line = lines[i];
// Iterate over each character in the current line
for(let j=0; j < line.length; j++){
let char = line[j];
// Check if the current character exists in the symbols object
if(symbols.hasOwnProperty(char)){
let token = {};
// Check that the current token is not empty
if(strToken.length > 0){
// Default type
let type = 'T_STRING';
// Is the token a float ?
let isNum = parseFloat(strToken);
if(!isNaN(isNum)){
type = 'T_NUMBER'
}
// Store the string token, type and line number into an object
token = {
value : strToken,
type : type,
line : i
};
// Add the object to the tokens array
tokens.push(token);
}
// Store the current charatcer as a seperate token
token = {
value : char,
type : symbols[char],
line : i
};
tokens.push(token);
// Clear the token and continue
strToken = '';
continue;
}
// Append the current character to the token
strToken += char;
}
// After the loop above completes, the strToken varibale may contain a token.
// Default type
let type = 'T_STRING';
// Is the token a float ?
let isNum = parseFloat(strToken);
if(!isNaN(isNum)){
type = 'T_NUMBER'
}
token = {
value : strToken,
type : type,
line : i
};
// Add the object to the tokens array
tokens.push(token);
}
return tokens;
}
let str = `print 5 +
( 2 * x )`;
let tokens = tokenize(str);
console.log(tokens);
// Output
[ { value: "print", type: "T_STRING", line: 0 },
{ value: " ", type: "T_SPACE", line: 0 },
{ value: "5", type: "T_NUMBER", line: 0 },
{ value: " ", type: "T_SPACE", line: 0 },
{ value: "+", type: "T_PLUS", line: 0 },
{ value: " ", type: "T_SPACE", line: 0 },
{ value: "(", type: "T_LEFT_PAREN", line: 1 },
{ value: " ", type: "T_SPACE", line: 1 },
{ value: "2", type: "T_NUMBER", line: 1 },
{ value: " ", type: "T_SPACE", line: 1 },
{ value: "*", type: "T_MULTIPLY", line: 1 },
{ value: " ", type: "T_SPACE", line: 1 },
{ value: "x", type: "T_STRING", line: 1 },
{ value: " ", type: "T_SPACE", line: 1 },
{ value: ")", type: "T_RIGHT_PAREN", line: 1 } ]
The code has increased significantly but if you follow it through and read the comments, you will realize that it's not too difficult to understand. Each character that we need to split on has its own token type. Additionally, there are two other types (T_STRING and T_NUMBER). A comprehensive lexer will be able to detect other types such as keywords and variables.
The lexer that we have created so far will work for simple expressions, but we want to develop a lexer for the Logo programming language. We need to add two more characters to the list of split characters in the symbols object. Update the symbols object to include [ and ] characters as shown below.
Listing 10
let symbols = {
' ' : 'T_SPACE',
'+' : 'T_PLUS',
'-' : 'T_MINUS',
'*' : 'T_MULTIPLY',
'/' : 'T_DIVIDE',
'(' : 'T_LEFT_PAREN',
')' : 'T_RIGHT_PAREN',
'[' : 'T_LEFT_BRACKET',
']' : 'T_RIGHT_BRACKET'
};
We now have a lexer function that we can use to tokenize Logo statements. In part two, we will develop a TokenCollection class that will encapsulate the array of tokens returned from the tokenize() function. By creating this class, we will be able to traverse the array of tokens using helper methods such as getNextToken() and getPreviousToken().
Continue reading Part 2 - TokenCollection Class
-
A JavaScript Implementation Of The Logo Programming Language - Part 2
Part 2 of A Javascript Implementation Of The Logo Programming Language. In the previous article I explained how to develop a simple lexer. In this part we develop a TokenCollection class to help traverse the array of tokens returned from the lexer.
10 June 2020 - 4224 views -
Generating Web API Keys
If you're building a REST API, chances are you're going to need to generate secure random API keys. In this article, I explain how to use the Node.js crypto module to generate random secure API keys.
29 May 2020 - 9971 views -
Port Scanner
A simple port scanner to scan a range of ports.
31 January 2020 - 5142 views -
Sorting Algorithms
An introduction to sorting algorithms.
29 November 2019 - 3829 views -
Simple Http Server
This article explains how to create a simple HTTP server using Node.js without using any dependencies.
04 September 2019 - 3473 views -
Reading From Console
Node.Js provides several ways to read user input from the terminal. This article explains how to use the process object to read user input.
16 July 2019 - 4155 views -
Difference Between const, let And var
This article explains the difference between const, let and var.
12 July 2019 - 3244 views